


Nature vs. Machine
Rethinking Computational Efficiency in the AI Era

A single ant colony can solve complex optimization problems while consuming less energy than a LED bulb. Meanwhile, OpenAI's GPT-4 training reportedly consumed enough electricity to power 15,000 American homes for a year. This contrast exemplifies a critical challenge in artificial intelligence: the massive energy costs of our current approach.
The AI industry's response to this energy challenge reflects a familiar pattern in technological evolution: When transformative technologies emerge, companies prioritize rapid scaling and market dominance over optimization—a "land grab" mentality where being first and dominantly large matters more than being optimal. This is happening now as major tech firms scramble to secure enormous power supplies for their AI operations:
AI is exhausting the power grid. Tech firms are seeking the miracle solution.
AI Needs So Much Power That Old Coal Plants Are Sticking Around.
While the rush to scale is understandable from a competitive standpoint, it raises a critical question: Will the recent success of LLM AI deepen our path dependency in energy-intensive computing architectures? Is the success of these models inadvertently closing the door on the concerted exploration of fundamentally different and more efficient approaches to computation?
There is reason to care about this question. Even ‘good’ innovation suffers from lock-in, and the stakes are often significant. For example, the LED, invented in 1962, took ~50 years to replace inefficient incandescent bulbs, costing trillions of kilowatt-hours in unnecessary energy consumption. We risk a similar or worse outcome with AI computation.
Before accepting this energy-intensive path as inevitable, it's worth reminding ourselves that nature accomplishes computational feats with remarkable efficiency. While tech companies race to secure nuclear power and revive coal plants, biological systems have spent millions of years evolving solutions that require minimal energy. This raises an important question: Will we overlook more elegant solutions in our rush to scale artificial intelligence?
The Remarkable Efficiency of Natural Compute
Humans do a lot of computing. Our brains can perform an exaflop of operations using just 20 watts of electricity, or the requirements of a light bulb. But computation in nature takes countless forms. Slime molds can solve maze-like problems to find the most efficient food-gathering routes. Bee colonies perform complex democratic decision-making when choosing new hive locations. Even "dead" materials like spider silk demonstrate computational properties we're just beginning to understand—adapting their structure in response to environmental conditions without a central processor.
Thus, before digital computers, there was significant 'natural' computing happening on our planet. And thanks to millions of years of evolution and competition for scarce resources, this compute was remarkably efficient. Figure 1 tells a surprising story: while artificial computation has grown exponentially since the mid-20th century and now seems ubiquitous, natural computation was, and likely still is, the dominant form of information processing on Earth.
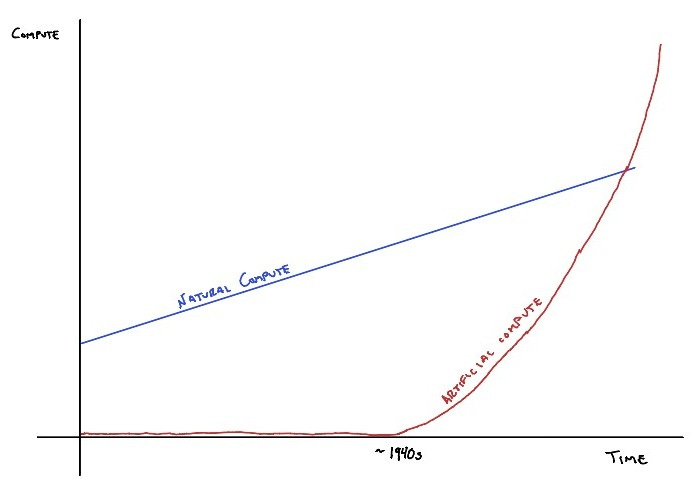
While nature achieved its computational prowess through elegant efficiency, digital computers took a different path—dramatically increasing computational capacity through brute force. The first machines required entire rooms of hardware for simple computations. Today’s smartphones are exponentially more powerful, but the same computational architecture drives both—i.e., the separation of processing, memory, and storage, with data shuttled back and forth. This architecture is highly scalable, but remains constrained by energy and efficiency limits.
The persistence of this architecture was not certain, but highly likely. As discussed in “The Evolution of Innovation,” human innovation is susceptible to lock-in. Once a viable ‘solution path’ is discovered, efforts to explore novel solutions diminish in favor of more economically-attractive incremental improvement, even if novel solutions could ultimately be better. This is partly explained by deficiencies in the way discount rates are used in finance and economics.
This stark efficiency gap between natural and artificial computation reveals a crucial insight: as we've shifted from natural to artificial compute over the last 80 years, we've actually made global computation less efficient in aggregate. Each artificial calculation costs far more energy than its natural counterpart. This inefficiency becomes particularly concerning as we enter the age of mass adoption of Large Language Models and artificial general intelligence.
The Ambiguous Future of the Cost of Artificial Compute
How will this inefficiency evolve as AI advances?
Technologists argue that the inefficiency is temporary—that learning curves will naturally drive down energy costs. While improvements are happening (like Google's recent 50% reduction in training energy), these gains are overwhelmed by the industry's appetite for larger models and more complex tasks.
A second-order viewpoint acknowledges the likelihood of even newer, incremental technologies in the foreseeable future; these will be similarly inefficient when first introduced. While the learning curves push down the average cost of maturing computation modes, new modes will enter at high average costs.
Beyond the near future, I propose two dramatically different paths, as illustrated in Figure 2. Path 1 represents the continued reliance on traditional, energy-intensive computational architectures, while Path 2 envisions a paradigm shift inspired by nature's efficient computing systems.
Charting a New Path Forward
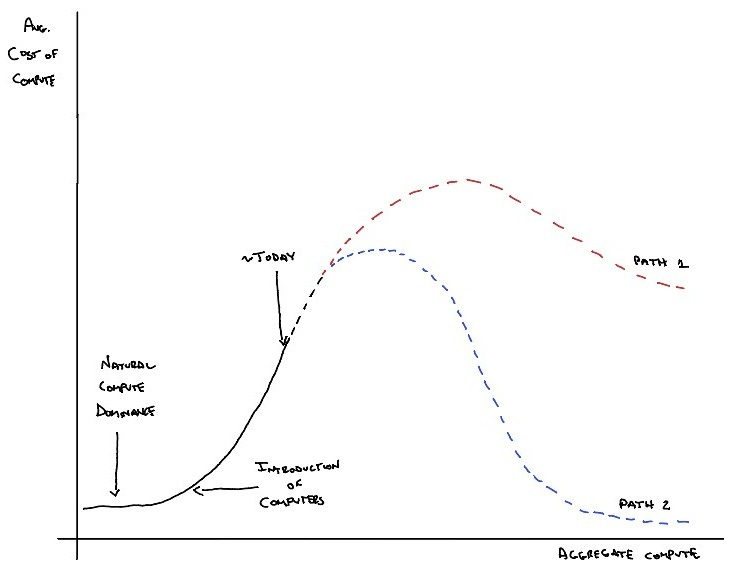
The two paths illustrated in Figure 2 represent different futures for computation. Path 1 reflects the momentum of sunk costs and institutional inertia. Even with incremental improvements, it remains locked into an inherently inefficient architecture.
Path 2 represents a two-pronged revolution in computation. The first prong involves mimicking nature's approach in our artificial systems—rebuilding our computational architecture from the ground up. For example, researchers are exploring:
DNA-based storage systems that can store all of YouTube's content in a sugar cube-sized container.
"Wetware" computers that use living neurons to process information with remarkable efficiency.
Quantum biological systems that might explain how birds navigate using Earth's magnetic field.
The second prong focuses on identifying and harnessing the vast amounts of natural computation happening around us. We're already seeing glimpses of this potential. For instance, Google's reCaptcha system cleverly takes comically easy feats of natural human computation (like identifying traffic lights in images) and uses them to train AI systems for difficult artificial-computation tasks.
Powerful forces will continue to steer the focus toward Path 1. Massive investments in current AI infrastructure—from data centers to software frameworks—create strong incentives to maintain the status quo. Breaking free requires more than technical breakthroughs; it demands a concerted effort to continue exploring the fundamental ways in which we see, acknowledge and approach computation. If we remain on Path 1, we risk prolonging a "dark age" of compute where:
AI advancement becomes limited to wealthy nations and corporations that can afford massive energy infrastructure.
Environmental costs of computation continue to spiral.
Innovation gets trapped in incremental improvements to an inherently inefficient paradigm.
Avoiding this future requires action across multiple fronts:
Research: Funding for interdisciplinary work combining biology, computer science, and materials science.
Policy: Carbon pricing that accounts for computational costs.
Incentives: For companies exploring radically different computational architectures.
The path we choose today will determine whether AI becomes a sustainable technology that democratizes computational power or an environmental burden that exacerbates existing inequalities.